

[ad_1]
:::info
This paper is available on arxiv under CC 4.0 license.
Authors:
(1) Zheyu Oliver Wang, Department of Aeronautics and Astronautics, Massachusetts Institute of Technology, Cambridge, MA and olivrw@mit.edu;
(2) Ricardo Baptista, Computing + Mathematical Sciences, California Institute of Technology, Pasadena, CA and rsb@caltech.edu;
(3) Youssef Marzouk, Department of Aeronautics and Astronautics, Massachusetts Institute of Technology, Cambridge, MA and ymarz@mit.edu;
(4) Lars Ruthotto, Department of Mathematics, Emory University, Atlanta, GA and lruthotto@emory.edu;
(5) Deepanshu Verma, Department of Mathematics, Emory University, Atlanta, GA and deepanshu.verma@emory.edu.
:::
Table of Links
- Abstract & Introduction
- Background and Related Work
- Partially Convex Potential Maps (PCP-Map) for Conditional OT
- Conditional OT flow (COT-Flow)
- Implementation and Experimental Setup
- Numerical Experiments
- Discussion and Reference
4. Conditional OT flow (COT-Flow).
In this section, we extend the OT-regularized continuous normalizing flows in [36] to the conditional generative modeling problem introduced in section 2.
\
Training Problem. Following the general approach of continuous normalizing flows [11, 19], we express the transport map that pushes forward the reference distribution ρz to the target π(x|y) via the flow map of an ODE. That is, we define g(z, y) = u(1) as the terminal state of the ODE
\
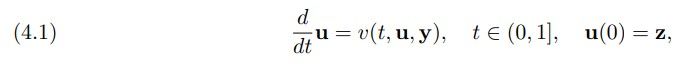
\
where the evolution of u: [0, 1] → R n depends on the velocity field v : [0, 1] × R n × R m → R n and
will be parameterized with a neural network below. When the velocity is trained to minimize the negative log-likelihood loss in (3.2), the resulting mapping is called a continuous normalizing flow [19]. We add y as an additional input to the velocity field to enable conditional sampling. Consequently, the resulting flow map and generator g depend on y.
\
One advantage of defining the generator through an ODE is that the loss function can be
evaluated efficiently for a wide range of velocity functions. Recall that the loss function requires the inverse of the generator and the log-determinant of its Jacobian. For sufficiently regular velocity fields, the inverse of the generator can be obtained by integrating backward in time. To be precise, we define g −1 (x, y) = p(0) where p : [0, 1] → R n satisfies (4.1) with the terminal condition p(1) = x. As derived in [58, 19, 56], constructing the generator through an ODE also simplifies computing the log-determinant of the Jacobian, i.e.,
\
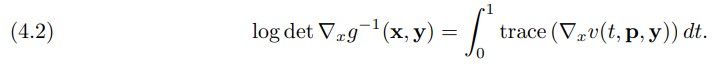
\
Penalizing transport costs during training leads to theoretical and numerical advantages; see, for example, [58, 56, 36, 17]. Hence, we consider the OT-regularized training problem
\

\
where α1 > 0 is a regularization parameter that trades off matching the distributions (for α1 ≪ 1)
and minimizing the transport costs (for α1 ≫ 0) given by the dynamic transport cost penalty
\
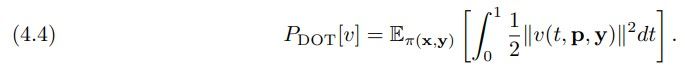
\
This penalty is stronger than the static counterpart in (3.4), in other words
\
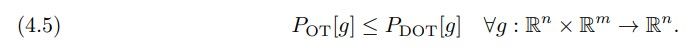
\
However, the values of both penalties agree when the velocity field in (4.1) is constant along the
trajectories, which is the case for the optimal transport map. Hence, we expect the solution of the
dynamic problem to be close to that of the static formulation when α1 is chosen well.
\
To provide additional theoretical insight and motivate our numerical method, we note that
(4.3) is related to the potential mean field game (MFG)
\
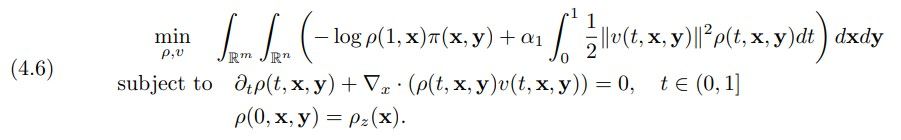
\
Here, the terminal and running costs in the objective functional are the L2 anti-derivatives of JNLL and PDOT, respectively, and the continuity equation is used to represent the density evolution under the velocity v. To be precise, (4.3) can be seen as a discretization of (4.6) in the Lagrangian coordinates defined by the reversed ODE (4.14). Note that both formulations differ in the way the transport costs are measured: (4.4) computes the cost of pushing the conditional distribution to the Gaussian, while (4.6) penalizes the costs of pushing the Gaussian to the conditional. While these two terms do not generally agree, they coincide for the L2 optimal transport map; see [16, Corollary 2.5.13] for a proof for unconditional optimal transport. For more insights into MFGs and their relation to optimal transport and generative modeling, we refer to our prior work [43] and the more recent work [57, Sec 3.4]. The fact that the solutions of the microscopic version in (4.3) and the macroscopic version in (4.6) agree is remarkable and was first shown in the seminal work [28].
\
By Pontryagin’s maximum principle, the solution of (4.3) satisfies the feedback form
\
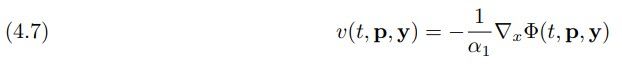
\
where Φ : [0, 1] × R n × R m → R and Φ(·, ·, y) can be seen as the value function of the MFG and, alternatively, as the Lagrange multiplier in (4.6) for a fixed y. Therefore, we model the velocity as a conservative vector field as also proposed in [36, 43]. This also simplifies the computation of the log-determinant since the Jacobian of v is symmetric, and we note that
\
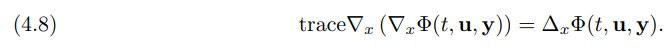
\
Another consequence of optimal control theory is that the value function satisfies the Hamilton
Jacobi Bellman (HJB) equations
\
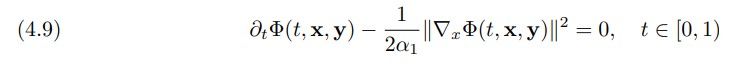
\
with the terminal condition
\

\
which is only tractable if the joint density, π(x, y), is available. These n-dimensional PDEs are
parameterized by y ∈ R m.
\
Neural network approach. We parameterize the value function, Φ, with a scalar-valued neural network. In contrast to the static approach in the previous section, the choice of function approximator is more flexible in the dynamic approach. The approach can be effective as long as Φ is parameterized with any function approximation tool that is effective in high dimensions, allows efficient evaluation of its gradient and Laplacian, and the training problem can be solved sufficiently well. For our numerical experiments, we use the architecture considered in [36] and model Φ as the sum of a simple feed-forward neural network and a quadratic term. That is,
\
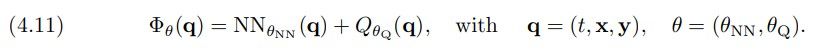
\
As in [36], we model the neural network as a two-layer residual network of width w that reads
\
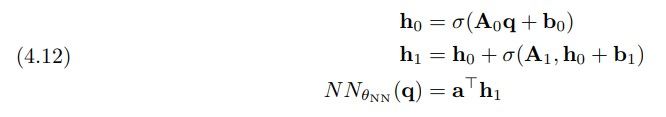

\
Sample generation. After training, we draw i.i.d. samples from the approximated conditional distribution for a given y by sampling z ∼ ρz and solving the ODE (4.1). Since we train the inverse generator using a fixed number of integration steps, nt, it is interesting to investigate how close our solution is to the continuous problem. One indicator is to compare the samples obtained with different number of integration steps during sampling. Another indicator is to compute the variance of ∇Φ along the trajectories.
\
Hyperparameters. As described in section 5, we randomly sample the width, w, of the neural network, the number of time integration steps during training, the penalty parameters α1, α2, and the hyperparameters of the Adam optimizer (batch size and initial learning rate) from the values listed in Table 2.
[ad_2]
Source link