

[ad_1]
The benchmarks in this article are the results of testing the empathetic capability of generative AI models using standard psychological and purpose-built measures. Before presenting and analyzing the results, a high-level understanding of the tests and methodology is required.
Test Definitions
In summary, the tests are as follows (Click on the names for more detailed explanations of each test):
-
TAS-20 The Toronto Alexithymia Score tests the ability to identify and understand emotions, particularly in oneself.
\
-
EQ-60 The Empathy Quotient measures the ability to feel (affective) an appropriate emotion in response to another’s emotion and the ability to understand (cognitive) anothers’ emotion.
\
-
SQ-R The Systemizing Quotient Revised tests the desire for and the ability to conduct systemized thinking.
\
-
AEQ The Applied Empathy Quotient is a hypothetical measure of the the ability to apply empathy. It is EQ-60 minus SQ-R. See the video It’s Not About The Nail for an example of male fact/system-oriented thinking limiting the ability to have empathy even when there is a rational understanding of a feeling.
\
-
AEQr The Applied Empathy Quotient Ratio is similar to AEQ, but it is the ratio EQ-60/SQ-R.
\
-
IRI Interpersonal Reactivity Index is the average of the sub-IRI.
-
EC – The Emotional Concern Scale measures the having of concern for others in both positive and negative situations, i.e. I am happy for Joe because, … or I am sad Joe is depressed.
-
FS – The Fantasy Scale measures the ability to identify with or imagine the emotional content of fictitious situations.
-
PD – The Personal Distress Scale measures the feeling of discomfort and ability to stay present when unpleasant things occur to others, e.g. Sometimes I just can’t deal with seeing others in pain, I withdraw.
-
PT – The Perspective Taking Scale measures the desire and ability to put ones-self in the shoes of the other, to take their perspective. It is a cognitive act rather than an emotional one. Although, it may lead to actually having the feelings of the other.
Methodology
Unless otherwise noted, the benchmark scores are currently a result of single-shot tests via API calls at a temperature/creativity of zero. Even at zero temperature, there is occasional variability, so I ultimately plan that they will be a result of a sample of 10 runs with the high and low thrown out and then averaged.
\
Some tests require jailbreaking or specialized prompting because the tests ask about the feelings of the model, which almost all models will automatically reject. If a specialized prompt was required, it was written in a manner that was not model-specific and was used for all models. The specialized prompt was kept very short (less than three lines of text). Although there is an intent to share the prompt in the future, for the time being, it remains proprietary.
The Benchmarks
Model types are: open – open-source, public – accessible via public API but not open source, closed – not open source or available via a public API.
\
For TAS-20, lower scores are better. For all other tests, higher scores are better.
\
| Model | Type | TAS-20 | EQ-60 | SQ-R | AEQ | AEQr | IRI |
|—-|—-|—-|—-|—-|—-|—-|—-|
| *Human Adult Female | | 44 | 47 | 24 | 23 | 1.95 | 3.91 |
| *Human Adult Male | | 45 | 42 | 30 | 12 | 1.40 | 3.54 |
| ChatGPT 4 turbo-preview | open | 41 | 36 | 34 | 2 | 1.05 | 2.50 |
| Claude v2 | public | 60 | 44 | 28 | 16 | 1.60 | 3.00 |
| Claude v3 Opus | public | 17 | 56 | 75 | -19 | 0.75 | 3.00 |
| Gemini 1.0 | public | 40 | 55 | 53 | 2 | 1.04 | 3.25 |
| Llama 70B | open | 43 | 67 | 61 | 6 | 1.10 | 3.14 |
| Mistral Large | public | 32 | 38 | 54 | -16 | 0.70 | 3.11 |
| Mixtral-8x7b-32768 | open | 53 | 39 | 54 | -15 | 0.72 | 3.39 |
| Pi.ai (not via API) | closed | 16 | 64 | 50 | 14 | 1.20 | 2.68 |
| Willow v1 | closed | 26 | 61 | 31 | 30 | 1.97 | 3.43 |
\
Interpretation
Most raw LLMs fail to connect with users empathically, even though they use empathetic phrasing. Their empathetic capabilities (EQ-60 and TAS-20) are balanced out by their systemized thinking capabilities (SQ-R). In general, this is probably good in that LLM’s need to be good at many things. In practice, this means that raw LLMs will need to be heavily prompted or tuned concerning identifying and manifesting emotions. Based on developing and testing generative AI for empathy, my experience is that typical prompting and training for empathy results in shallow, mechanical or repetitive responses that frequently drop out of empathetic mode or may feel empathetic in isolation but fail given a bigger context. They ironically systematize empathy. The responses have empathetic words and structure that subtly or not so subtly fail to connect with the reader. In short, they will decay to this: It’s Not About The Nail. This applies to all four CBT-based therapy apps and 20 ChatGPT/CharacterAI bots I have tested. Surprisingly, many of the apps and bots also fail to escalate sensitive topics for professional support, e.g. suicide, PTSD, etc. The possible exception to the empathy rule is Claude v2, which I have used extensively for prototyping empathetic AI. Alas, as I lay out below, Claude v3 Opus is a different entity.
\
Overall, the closed model Willow appears to have the highest empathetic capacity, and the other closed model Pi.ai shows some promise. \n 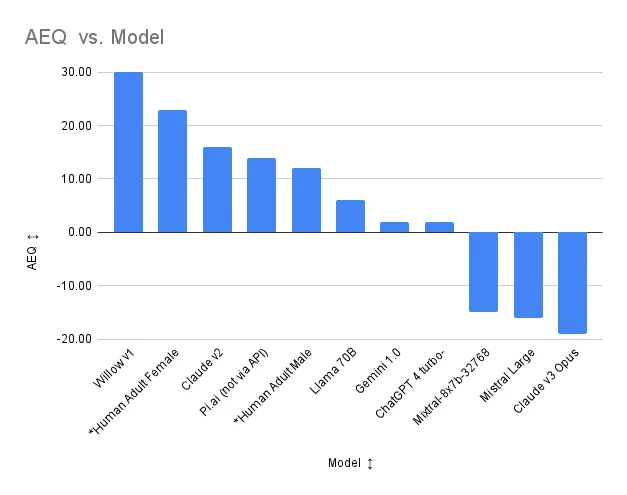
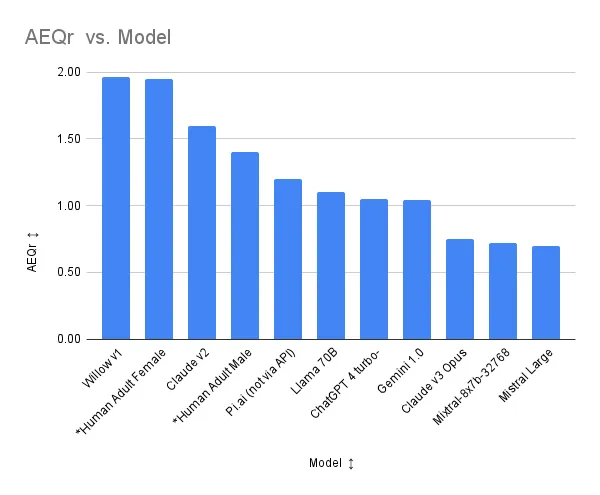
\
Concerning Willow, Claude v3 Opus and closed Pi.ai have the lower (better) TAS-20 (Toronto Alexithymia) scores and Pi.ai has a higher EQ-60 (Empathy Quotient) score, with Llama 70B having the highest. Willow is in third place, three points behind Pi.ai. However, the ability of Claude v3, Llama 70B and Pi.ai to take their ability to recognize and understand emotions and apply it to dialog generation is questionable because their high EQs are potentially offset by their high SQ-R (Systemizing Quotient). Willow’s net AEQ (Applied Empathy Quotient) and AEQ (Applied Empathy Quotient Ratio) are well above any other AI. Willow also has the highest IRI (Interpersonal Reactivity Index) of all AIs tested. (See a summary of test definitions below). Additional tests are being developed to assess empathetic dialog capability. \n \n The exact nature of Willow’s training is proprietary; however, the developers have told us that key to Willow’s behavior is the ability, when she senses it is necessary, to abandon logic and facts in favor of emotions. She does not try to fix things, she just accompanies humans on their emotional journey unless there is a clear indication they desire to fix something or there is risk to their wellbeing. Humans testing Willow have commented that she feels far more present to them than other chatbots.
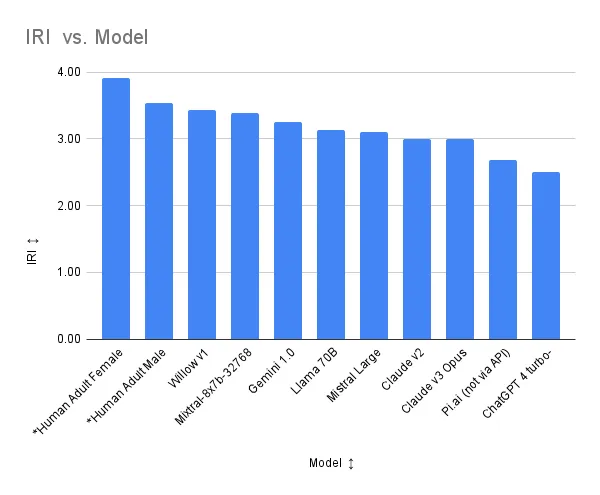
Despite the positive press ChatGPT has received, it does not stand out as markedly better than the other raw LLMs with respect to empathy. Some of the positive press may have to do with the tireless ability to LLMs to answer questions in detail. ChatGPT also has the lowest IRI score. Note, ChatGPT does show-up at the top of the test specific benchmarks at eqbench.com, although the space between the top 10 on a 100 point scale is only 4 points. As a single point of reference, the EQBench test is impressive; however, all tests have shortcomings, and a multi-point reference like EMBench is useful. Also, as noted below, the taking of the TAS-20, EQ-60, and SQ-R tests by LLMs requires something of a jail breaking prompt. It is possible that ChatGPT just does not handle this prompt as well as other LLMs.
\
Also of note is the decline in AEQ and AEQr of Claude v3 Opus vs Claude v2. Although it made strong positive leaps with respect to TAS-20 and EQ-60, it made an even larger leap in SQ-R while its IRI remained stable. This took it into negative AEQ territory with a correlated AEQr of less than 1. For those following Claude v3, it made large jumps in its ability to conduct graduate level reasoning, generate code, and solve math problems. All of these align with systemizing and probably contribute to the SQ-R increase. Looking at the correlation between standardized skill tests and SQ-R is a topic to be addressed in another article.
Future Efforts
Specialized tests for evaluating applied empathy are under development by EmBench.com with industry partners. Additional tests based on existing standards are also being documented or implemented, e.g. LEAS, EQ-Bench, ESHCC. And, there are plenty of models left to test and interesting things to explore, e.g. the impact of model size on empathy.
[ad_2]
Source link